15.2.4. Computing users to pass on to
The situation in Figure 2 is easy to comprehend. This is less so, however, in Figure 3. We can explore the graph by building a table with user roles on the rows and columns, and the paths between them in the cells (paths are expressed as user role nodes to pass on the way).
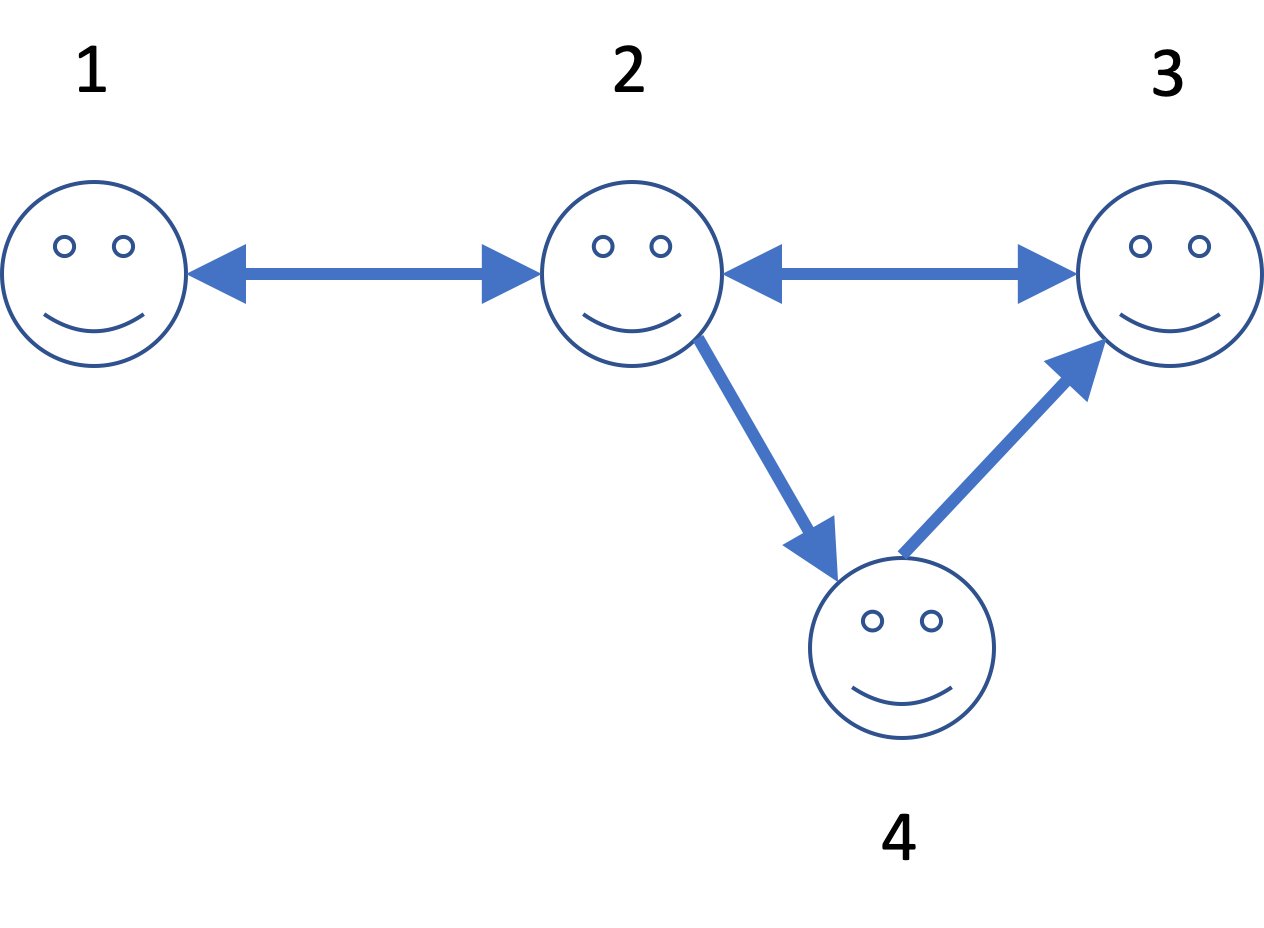
Figure 3 A more complicated user graph. We’ve omitted the non-user role R. However, all user roles have a perspective on it.
| 1 | 2 | 3 | 4 | |
|---|---|---|---|---|
1 |
2 |
2 |
||
2 |
||||
3 |
2 |
2 |
||
4 |
3, 2 |
3 |
Table 1 shows us that we have to pass through node 2 in order to reach node 3 from 1. This can easily be verified in the graph. Less obvious is the path from 4 to 1: it is through 3 and 2.
Here is how we use the paths table to create deltas that are passed on:
-
We start with the user role authoring the change. This we use to index a row in the table.
-
We then determine the destination of the delta (according to the perspectives of the peers). This we use to index a column in the table.
-
We then add to the delta the user types we find in the cell we’ve located.
In many cases above, there are no intermediate user types. But if an instance of user type 1 adds an instance of a role R, we create a delta, add user types 3 and 4 to it and send it off to all instances of user type 2 that we know about.
An instance of user type 2, upon receiving that delta, notes that it contains user types (3 and 4). It looks up all instances of those types and sends the delta to them, after removing user types 3 and 4. Obviously, the instance of type 2 also modifies its local store by adding the new instance of R!
An instance of user type 3 or type 4 receives the delta and just modifies its local store.
This is a general principle: it will work in every conceivable situation. We will explore more examples below. It depends, obviously, on the user role graph and the paths table.
15.2.4.1. How to handle multiple paths
It may happen that there are more than one way to connect two user nodes. In fact, Figure 3 contains a few examples. We can reach node 3 directly from node 2, but also via node 4, for example.
This is an easy case, as the first path is shorter than the second. We prefer shorter paths.
But we may have situations where two paths of equal length exist. In such cases it seems tempting to choose one at random. However, we deal with the type level here. It may well be that on the instance level one path may exist while the other is absent. So we should use both paths.
15.2.4.2. Optimization
Let’s reconsider the example we worked out above where an instance of user type 1 adds an instance of a role R that can be seen by roles 2 and 3 as well. What if there are multiple instances of user role type 2? If we send the delta to all instances, all will send it on to instances of user role type 3. This doubles the load on those instances while it achieves nothing extra. In fact, only one of them needs to do the task.
In general it is not easy to coordinate work among the peers in a distributed system, but here we are in luck. The instance of role 1 that created the change can act as coordinator by
-
Creating an instance of the delta with user role type 3
-
And creating an instance of the delta without it.
It then sends the first delta to just one instance of user role 2, and the second delta to all others. Thus, it burdens just a single peer with the task to pass the information on to instances of user role type 3.
It may send the pass on instruction to multiple instances of role 2 to increase the chance that it is sent on promptly (not all peers will be online, the more receive it the sooner it will arrive at its final destination).