6.2.5. Filtered queries
A quick refresh: a query, like functions do, has an origin domain and target range. In the expression filter source with criterium the source expression is a function that operates on the query domain and the resources that are computed with it lie in its range. The criterium expression must be a Boolean function and only those resources in the range that map to true with the criterium are in the end result of the filtered query.
The filter allows some values or resources to pass while it retains others. If we think of a filter in a query as a step of its own, it is a function whose domain and range are, by definition, equal. This implies that filter and its inversion have the same type. Consequently, to invert a filter in a query, we don’t actually change the filter operation itself: it serves just as well 'backwards' as 'forwards'.
However, a filter is a query step with a query as parameter value. The query yields a Boolean result. It maps each value of the sequence that is passed to the filter to true (letting the value pass) or false (retaining it). As the objective of query inversion is to find out, for each mutation of the structure of contexts, roles and their properties, whom to send a delta describing that mutation, this also applies to the filter step query parameter. We deal with that by appending the filter parameter query with its source of elements to judge and then invert the result. As a consequence, when on the instance level something changes in the criterium, we can just apply the entire inverted query at that point in the type chain to find the contexts that are instances of the domain of the query.
Remember again that we 'kink' an inverted query at each step, producing from a single inverted query with n steps exactly n 'kinked' queries. In the paragraph on storing inverted queries, we have carefully analysed in what type we store each of these. How do we handle this new filter step?
If we encounter a kinked query whose backwards step is:
{first source step} << filter criterium << {last criterium step}
we store it twice. Once as
{first source step} << {last criterium step}
and store it in the way described above, depending on the last criterium step, and once as
{first source step} << filter criterium
and store that depending on the first source step. Now, as we have seen, in three of the four cases we actually omit the first step as we store the kinked query. What are the consequences for the second case, when we’ve tacked a filter step onto the backwards part? Let’s take one example and analyse it.
Suppose the first source step was filled R. Instead of applying that step to the filler, we remove it from the query we store and apply the result directly to the filled role. Remember that in runtime we have both the filler and filled role at hand (both are in the delta that describes a new fills relationship). But the criterium is constructed so as to apply to the filler role, not to the filled role we now are poised to apply it to. For that reason, before storing the inverted query, we modify the criterium step by prepending the filler step to it. The filler step is functional, so we do hardly introduce overhead.
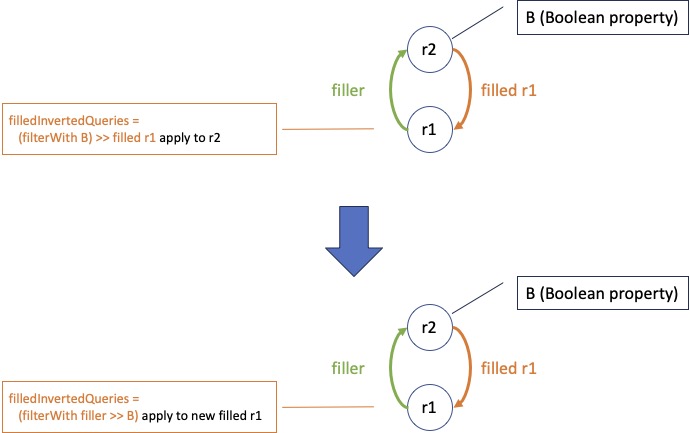
Figure 2. The upper part of the picture shows the situation without optimalisation. The lower part shows how, after omitting the first backwards step, we have to add its inverse to the criterium to preserve semantics.
In this way, we keep the runtime algorithm intact. An alternative would be to determine, runtime, each time we apply a backwards query, whether it starts on a filter step and, if so apply it to the filler instead of the filled role. This would introduce complexity in the runtime. But, more important, we would eliminate the efficiency step we introduced with removing the step from filler to filled. Remember that a role can fill many others, so we would have a 'fan out'.
Mutatis mutandis, the same reasoning applies to filtered backwards queries whose first source step is filler or role R.
6.2.5.1. Why create two inverted queries out of one?
But let’s return to the fact that we store two inverted queries while we only processed one. The reason for this has to do with the way we handle composition when we invert the original query. Both the left part and the right part of a composition may result in multiple kinked queries. We combine those results by treating it like a kind of array multiplication: we combine each part on the left with each part on the right (under the condition that the domain and range of both parts comply). We then add the inversions of the left part to the end result, except when the right part starts on a filter. Why? Because we want to tack the filter on the left part inversions (as shown above). So we leave out the left parts here and recreate them when we store the inverted queries, as shown above.
Why not add the filter to the left parts during the composition inversion? Because it is complex and depends on the kind of first steps, as shown above. We actually had the machinery to do the case analysis in the algorithm that stores, so we re-used that.
6.2.5.2. We are not yet done
Alas, the analysis given above is not complete. Let’s give an example, taken from a model to test the inversion of queries with filters:
case FilterTest
user ZietMinder filledBy sys:PerspectivesSystem$User
perspective on SommigeDingen
props (Naam) verbs (Consult)
thing AlleDingen (relational)
property Naam (String)
property Zichtbaar (Boolean)
thing SommigeDingen = filter AlleDingen with Zichtbaar
The user role ZietMinder is a peer of users in another role. The objective of the test is to make sure that ZietMinder receives all deltas to give him access to all instances of SommigeDingen that this model promises. Now consider the situation of an instance of AlleDingen with name 'Ding 1'. ZietMinder users will not see this instance, as long as its Zichtbaar property is not true. However, what happens under the regime described above, when Zichtbaar is made true, is that these users will just receive the delta describing that property change. But they also need the deltas that describe how to add the instance 'Ding 1' in the first place! Why does this not happen?
This situation is reminiscent of what happens when one fills a role instance R1 with R2. Users with a perspective on a calculated role that has depends on this fills relationship, should receive all deltas that describe R2 (and everything that follows according to the query definition). We handle that in the PDR by executing the query interpreter on the forwards part of the kinked query stored at the filled type (the type of R1). So we would execute the forwards part on R2, collect all assumptions (roles and contexts visited) and map them to deltas.
Similar reasoning applies to this situation. This is the algorithm that has yet to be implemented.
First of all, we have to be able to tell whether the forwards or backwards part of a kinked query has a filter step, somewhere (we might add a property to the data structure that describes kinked queries: notice that would constitute a change to the DomeinFile structure requiring recompilation of all models). Then:
-
if the backwards part contains a filter:
-
apply the backwards query, using the query interpreter, to the applicable instance;
-
if there is a result (consisting of users and contexts), construct deltas from it and add them (and the original delta) to the current Transaction for all users (notice that, by definition, all results would satisfy the criterium applied somewhere in the backwards query).
-
-
if the forwards part contains a filter:
-
apply the forwards query, using the query interpreter, to the applicable instance. if there is a result R:
-
apply the backwards query
-
for any users resulting from that, send all delta’s based on R (and include the original delta)
-