6.2.3. Where we store inverted queries and how we use them
|
Note
|
The design described below applies to PDR version 0.24.1 and earlier. From then on, inverted queries are stored not with the model but in a separate database. See the paragraph on storing inverted queries in Couchdb for details. The paragraph below has not been updated!! |
6.2.3.1. Where we store
Queries are inverted in design time, as we process a model. As we follow an inverted query one step back to its origin through the web of types, we store the remaining query with the node we’ve arrived at with that step, along the way.
We can pass through a role instance node in a number of ways:
-
From its context, using the role <type> step;
-
To its context, using the context step;
-
From its filler, using the filled role <type> step;
-
From a role that binds it, using the filler step.
We store inverted queries with Role types, except for those that start with a role <type> step: these are stored with context types.. We let the type of the first step of the inverted query determine the member of the type where we store it: so if the first step is filler, we’ll store the inverted query in fillerInvertedQueries.
The table below gives the overview for all four steps.
| step type of inverted query | query stored in | of | Query applied to |
|---|---|---|---|
filled R |
filledInvertedQueries |
filled type |
filled* |
filler |
fillerInvertedQueries |
filled type |
filler* |
context |
contextInvertedQueries |
role type |
role |
role R |
roleInvertedQueries |
context type |
role* |
|
Note
|
rows where the column 'Query applied to' is marked with an asterisk, have the first step of their inversion removed. Take the role R step as an example. The inverted query will be applied when a new instance of R is added (or removed). We just have to follow the rest of the inverted query from that new instance; nothing changes for the other instances.
|
Figure 1 illustrates all four cases.
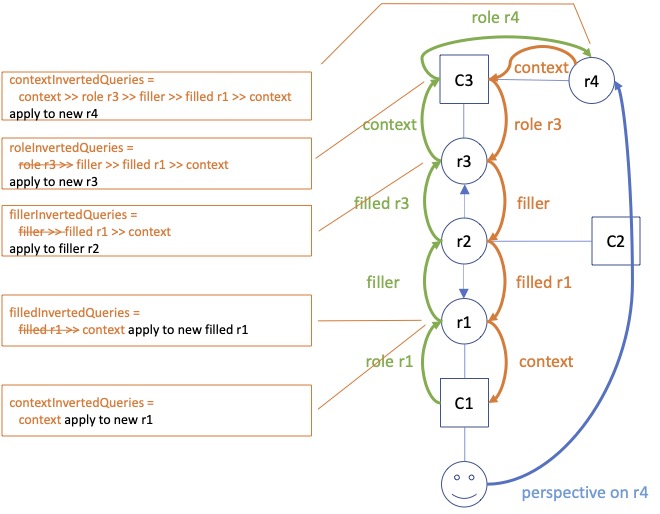
Figure 1. Inverted queries in relation to various nodes in the graph. Green lines and text represent the original query; red lines and text represent the inverted query. The user has a perspective on role (type) r4. Blue lines start in a filler and end in a filled node. The boxes show inverted queries as stored in various members of role types.
6.2.3.2. What we store and what we apply it to
Consider the example of the inverted query stored in roleInvertedQueries of c3 in Figure 1. The query step that we would apply to c3 would have been: role r3. So we would expect roleInvertedQueries to hold the full query
Role r3 >> filler >> filled role r1 >> context
That will take us from c3 to c1, as intended. Yet, as the diagram shows, we skip the first query step (storing just filler >> filled role r1 >> context) and apply it to r3 (instead of c3). Why?
We will apply the inverted query when we handle a ContextDelta. Let’s assume the delta represents a new instance of r3. Now the whole point of applying the inverse query is to find contexts and roles that are now available to the user having the perspective, but were not so before. In other words: a new path has been formed and we want to travel that to its root. Obviously, the new connection must be part of the path we travel. But then we should start at the new instance of r3! Otherwise, on starting with c3, we would also travel down all paths that begin with siblings of the new instance.
Hence we shorten the query and start at the new role instance.
A similar consideration holds for the inverted query stored in filledInvertedQueries role stored in r1. Instead of applying the full inverted query to an instance of r2, we apply the shorter version to the new filled role of type r1. This is because there can be many filled roles of r2!
For queries stored in fillerInvertedQueries, the same reasoning applies.
|
Note
|
Queries that start with the filled step are not stored with the type of departure.
|
Looking back, we see that a query is stored with the node of departure of the first step: is it the context step, we store in the role; is it the role step, we store it in the context. The filler departs from the filled node and so we store such queries there. So why do we not store queries that start on the filled step with the filler node? There are two reasons:
-
the filler type might be from another model. That would require us to change that model, but that runs into problems (e.g. it might be authored by a different person!)
-
if the end user fills the filled node not with an instance of filler but with a specialisation of filler, the inverted query would be missed entirely.