15.4.3. Solution
All this means that the implementation up till version v0.12.0 wass incorrect.
15.4.3.1. Separating groups of inverted queries conceptually
Inverted queries starting on a property
We should be able to distinguish between Inverted Queries on a Property type for the various EnumeratedRole types that they are added to. Currently, Inverted Queries are stored in an Array in the representation of Property. This we will change to an Object, where the keys represent EnumeratedRoleTypes.
Inverted queries starting on a context
When a new role instance is added to a context, we must follow queries of which that segment from context to new role instance is a part. The relevant Inverted Queries are stored on the Context type in the invertedQueries collection (there is no need to make this name more discriminative, as only one step (the role step) leads away from contexts). A ContextDelta gives us both the context instance and the role instance. In principle, we need to identify the type of the role instance with a RoleInContext; but, unsurprisingly, its Context type part will by construction be the type of the Context instance. Hence, we can properly recognize InvertedQueries fitting our Delta by the EnumeratedRoleType alone, in the collection of inverted queries on the appropriate Context type.
A role type may have more than one instance in a context instance. Because we do only need to evaluate the new (or removed) segment, we do actually not apply the inverted query from the context instance, but from the new (or deleted) role instance. This is somewhat confusing. We treat these queries as if they start with the context step, while they actually do not.
Inverted queries starting on a role
Let’s reconsider the various Inverted Queries that are stored with an EnumeratedRoleType. We categorize them according to their first step, that determines whether the path leads to the role’s context, its filler, or the roles it fills.
For queries that start with a context step, the relevant queries in the model are those that start on the RoleInContext that we derive from the ContextDelta. But as we store the InvertedQueries on the EnumeratedRoleType, we can separate out the relevant inverted queries with the Context type alone, similar to the role step discussed above.
Inverted queries between two roles
The fills step and the filledBy step move between two role instances. We can derive a RoleInContext from both and that means we can find the relevant inverted queries by the combination of these two RolInContexts.
15.4.3.2. Representation of Queries
We represent queries with a QueryFunctionDescription that gives us the domain, range, function, and some meta-properties and the argument expressions that supply values to be bound to function parameters. Domain and range are constructed as an Abstract Data Type (ADT) of a base type and role domains are based on EnumeratedRoleTypes. We see now that they must be based on RoleInContext.
15.4.3.3. Runtime indexing
Let’s illustrate the above with some examples.
Consider an Aspect Role Driver, to be added to both a Car and a Train context type. Suppose both contexts have other user roles that have a perspective on the Driver. This would establish inverted queries for both contexts on the Driver role. Clearly, we must be able to distinguish the queries for the Car context type from those for the Train context type. In other words, we have a RoleInContext Train Driver and a RoleInContext Car Driver.
Runtime indexing: context step
In runtime, how do we index? We should subdivide inverted queries that depart from a role instance with the context step according to the RoleInContext that is a combination of the EnumeratedRoleType and the ContextType that is reached. However, by construction, the role type will be the type that we store the queries on. So we can leave it out and just use the ContextType to subdivide the inverted queries.
That is, we can choose the right subcollection of the contextInvertedQueries on the Driver role by using either the Train or the Car ContextType.
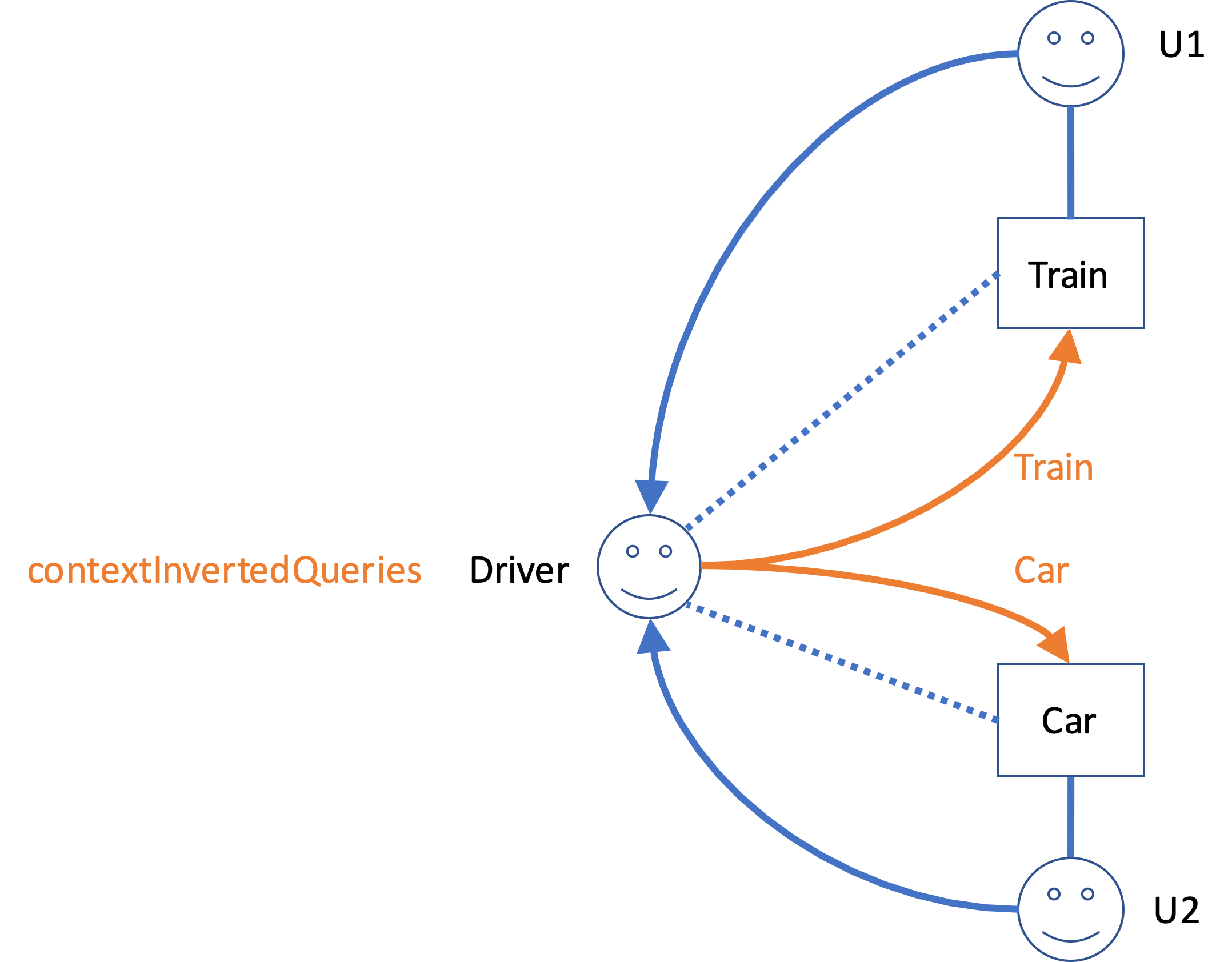
Figure 2. The inverted queries stored in contextInvertedQueries (orange lines) in the Driver Role type should be indexed by the context type of their endpoints, or, equivalently, the context type of the role type of departure.
Runtime indexing: role step
Inverted queries that, conceptually at least, start with the role step, are stored with a Context type. They are subdivided according to the EnumeratedRoleType that they lead to (as explained above).
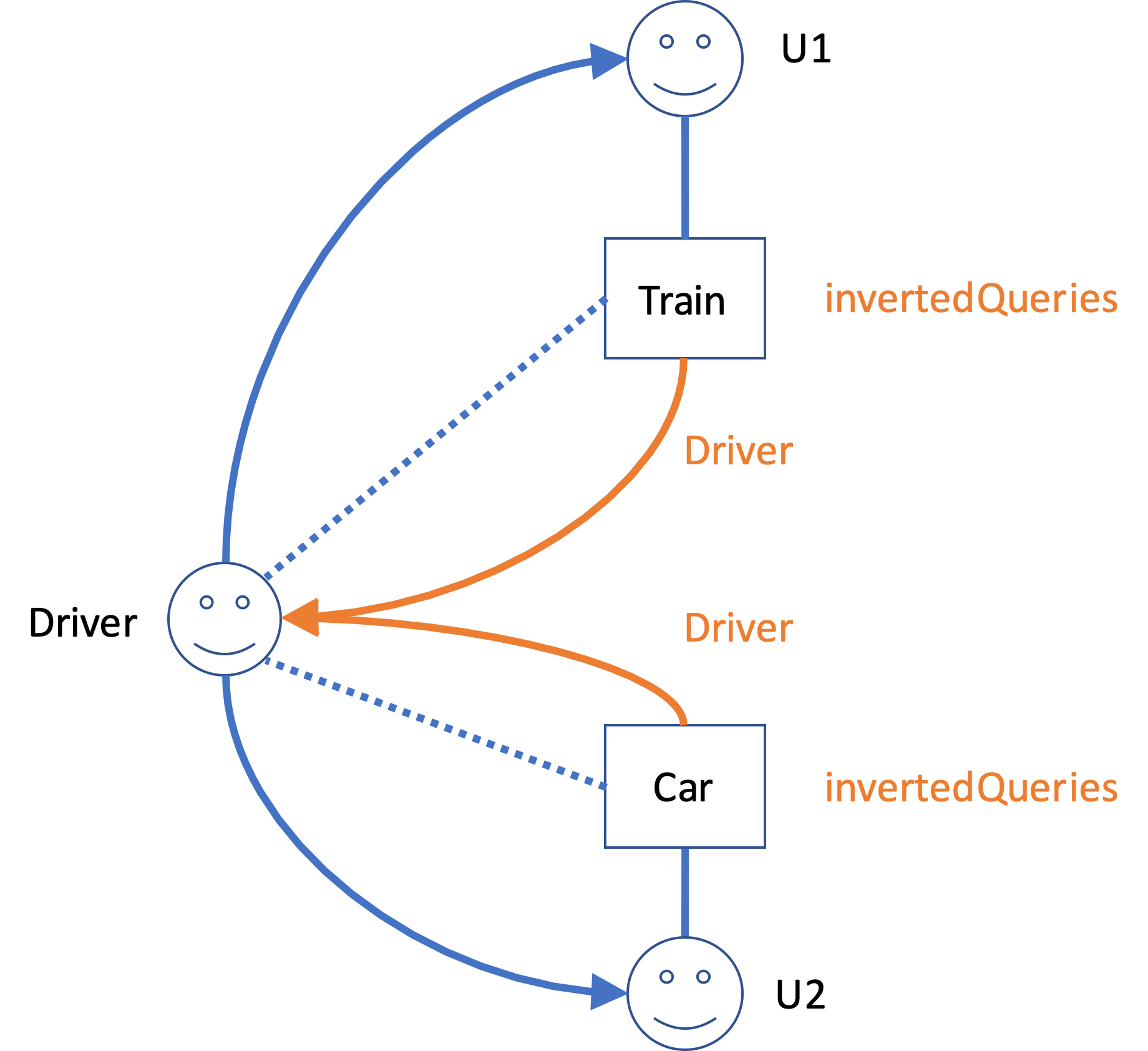
Figure 3 In this figure, the perspectives are the other way round (this is a contrived example, as Aspect roles would not have perspectives on roles in contexts to which they are added. However, it serves to illustrate the principle. We see that inverted queries, stored with the Context type, should be indexed with just the EnumeratedRoleType they lead to.
Runtime indexing: filler step
Inverted queries that depart from a role instance with the filler step, are stored in the filledByInvertedQueries collection on the EnumeratedRole type. What subcollections should we distinguish? Remember that we must make sure that we only apply inverted queries that contain the segment that is described by the Delta. This is now defined by two role instances, or, in other words, two RoleInContext instances.
As the step has a direction (from Filled to Filler), we will combine (apply) the RoleInContext instances in that order. Notice that, by construction, the first of these will always have the type of the EnumeratedRole that the collection is stored in. So we could do with just its ContextType. This is not true for the second RoleInContext instance: either of its components may vary freely. Thus, we have three keys, applied in this order, to find the right subcollection of inverted queries:
-
The ContextType of the Filled role in the Delta, or, in type time, of the Domain of the QueryFunctionDescription;
-
The ContextType of the Filler role in the Delta, or, in type time, the ContextType of the Range of the QueryFunctionDescription;
-
The type of the Filler role in the Delta, or, in type time, the EnumeratedRoleType of the Range of the QueryFunctionDescription;
For the implementation we have a number of representation choices, ranging from three nested Objects to a single Object with a key that is the combination of the string representation of the three keys, to a Map with a key constructed of the three types.
Runtime indexing: fills step
Inverted queries that depart from a role instance with the fills step, are stored in the fillsInvertedQueries collection on the EnumeratedRole type.
The reasoning is symmetrical to that for the filler step. Again, we must use two RoleInContext indices; again, we can ignore the EnumeratedRoleType of the first of these. However, the direction is inverted. So we have:
-
The ContextType of the Filler role in the Delta, or, in type time, of the Domain of the QueryFunctionDescription;
-
The ContextType of the Filled role in the Delta, or, in type time, the ContextType of the Range of the QueryFunctionDescription;
-
The type of the Filled role in the Delta, or, in type time, the EnumeratedRoleType of the Range of the QueryFunctionDescription;
Again, like with the role step, the fills step has cardinality greater than one (it can fill many other roles). For this reason we shorten the inverted query and the runtime applies it to the filled role – not to the filler role.
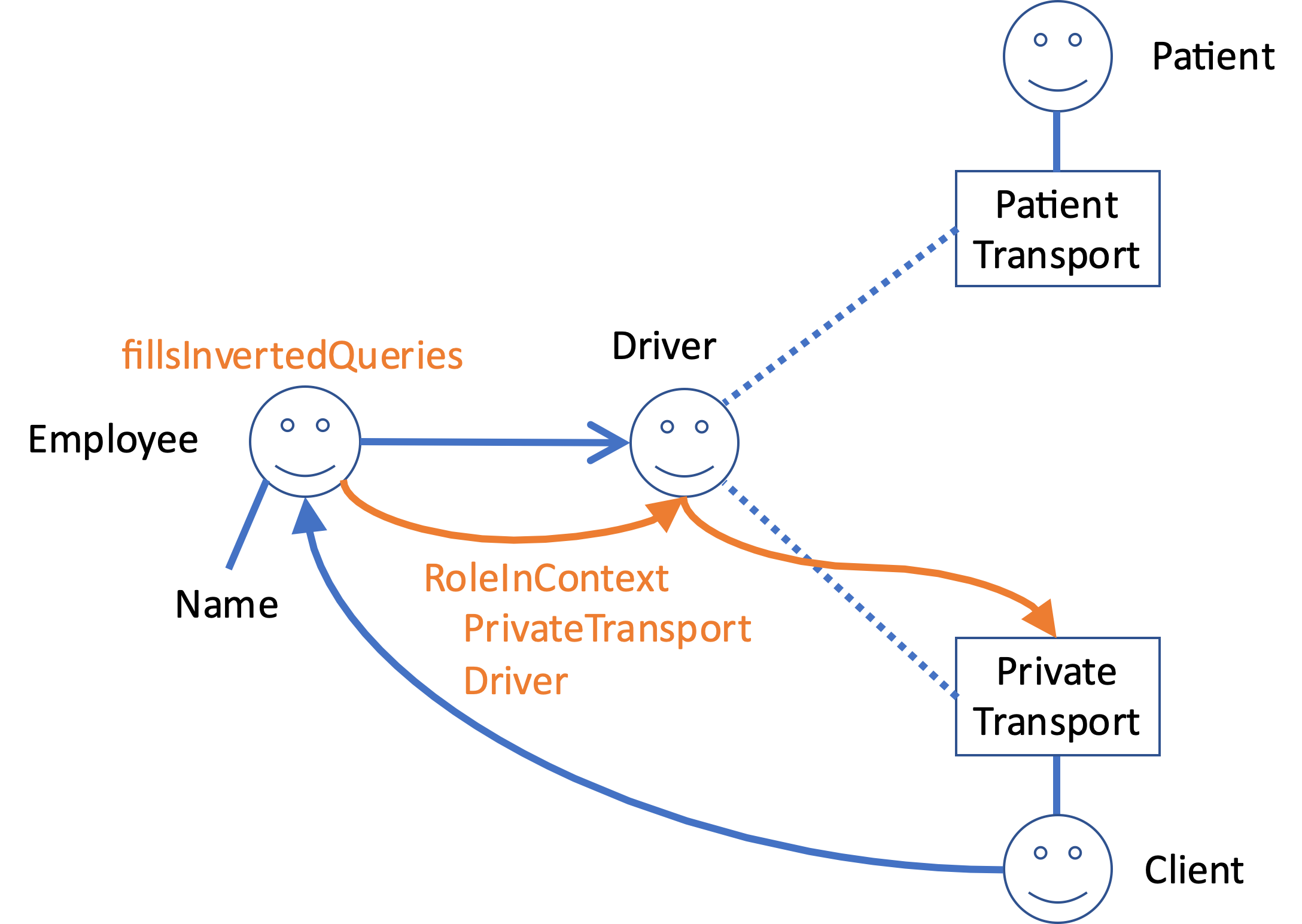
Figure 4. The Employee (of, say, a taxi company) fulfills the Driver role in both transport of severely ill people and for privatel rides. Now suppose (for the sake of the argument) that the Client of such a private ride has a perspective on the Driver, including his name, but the Patient does not. The inverted query that is stored in the fillsInvertedQueries collection of Employee actually starts on the Driver role instance (because the binder step has cardinality greater than 1). But clearly, we should index this collection of inverted queries with RoleInContext PrivateTransport Driver, order to prevent the system from informing Patients when the Driver role is filled. Actually, we should also use the Context Type of Employee to cover the situation where Employee was used as Aspect as well.
15.4.3.4. Compile time indexing
In compile time, we invert the description of a query. We then cut the resulting path(s) at all steps and store those ‘cuts’ in collections of inverted queries on the various types (Contexts, Roles, Properties). On storing them, we must use the same keys we use when we retrieve them. How do we compute these keys in compile time?
Actually, it is more like ‘kinking’ the query path at all steps. So a query with n steps results in n-1 kinked queries. Each consists of two parts: a part going backwards (against the direction of the original query) and forwards (so it is the rest of the original query from that point). However, in this text I just call them ‘cuts’ and you can think of it of all subpaths of the inverted query leading to its end.
Let’s step back for a moment and contemplate our predicament. What we need to do is to add the cuts to the DomeinFile in such a way that we can find the relevant ones when we have a Delta on our hands. The strategy to follow depends on the Delta and the first step of the inverted query.
Keys for the Value2Role step
A Property query calculates, for a given role, the values of a particular PropertyType. When we invert that query it starts with the values. However, values are not stored as indexable entities in the PDR. Instead, we skip the first step of the inverted query and start with the role instance. Hence we can derive from a RolePropertyDelta on the instance level a ‘PropertyInRole’ element on the type level: the combination of a EnumeratedRoleType and a EnumeratedPropertyType. When we store a particular cut on a Property, we use that as a key to file it under. Actually, the EnumeratedPropertyType part will not discriminate anything, because it will always be equal to the type of the Property we’ve stored the cuts in. So we can make do with just the EnumeratedRoleType part.
It enables us to distinguish a Property in its lexical context (let’s say A) from that same Property in some Aspect role context (say, B). Suppose that for B we have a CalculatedProperty that computes the average of the Property’s values. Now, when that value set changes on an instance of B, we should recompute the average. But imagine that the value of the property changes on an instance of A. If we had not filed the cut under the key B, we were doomed to recompute the cut for A’s instance, too. As a consequence, we might end up informing some peers that have nothing to do with that change.
In compile time, we have a QueryFunctionDescription whose Range is an ADT RoleInContext (it is the inversion of a PropertyGetter QueryFunctionDescription, whose domain is an ADT RoleInContext. From that range we take all EnumeratedRoleTypes and store the cut on the Property under each of those as key. This we do for all EnumeratedPropertyTypes we find in the domain of the QueryFunctionDescription.
Keys for the role step
When the inverted query approaches a role from the other direction (from the context, using a role step), we have a similar story. The QueryFunctionDescription has a Range that is an ADT RoleInContext. Since the domain can be a complex ADT holding many ContextTypes, the range can be a complex ADT holding many RoleInContexts.
For each of these RoleInContexts, we store the cut on the ContextType under the EnumeratedRoleType.
Keys for the context step
When we traverse the connection between role and context in that direction, we have a QueryFunctionDescription with a Range whose value is an ADT ContextType. It’s Domain is an ADT RoleInContext. For each of the RoleInContexts we find in that Domain, we store the cut in its EnumeratedRole, under its ContextType.
Keys for fills and filledBy steps
A RoleBindingDelta describes a particular segment of the role- and context instances network. Moving into type space, we can project that instance segment on a particular segment of RoleInContext nodes. We’ll call that pair the TypeLevelSegment and its first RoleInContext its start and the last its end.
Our task, then, runtime, is to find for a TypeLevelSegment the relevant cuts: the TypeLevelSegment is our key, on a conceptual level. So how do we find those cuts in the DomeinFile? How should we add cuts to the DomeinFile so we know the key will return the ones we look for?
A QueryFunctionDescription holds a domain and a range. These are abstract datatypes of RoleInContext. The simplest possible case would be a simple type (each consisting of a single RoleInContext) for both domain and range: then the queries’ domain and range form a single TypeLevelSegment. Mapping the TypeLevelSegment derived from the RoleBindingDelta is easy in that simple case. The general case, however, is that a pair of ADT’s represent multiple TypeLevelSegments.
What if the domain of a particular cut consists of a SUM of two RoleInContexts? A moment’s reflection learns us that if the start of a particular TypeLevelSegment is either of these two RoleInContexts, this cut should be evaluated (meaning that when we modify an instance whose type is the start of the TypeLevelSegment, we should evaluate the cut). After all, the elements in a SUM represent alternatives. So now we can derive two TypeLevelSegments from the QueryFunctionDescription. Should our RoleBindingDelta map to either of them, we must evaluate the inverted query.
A PRODUCT of two RoleInContexts represents not alternatives, but composition. We should consider the product of two role instances to be a single role instance with combined properties. Again, if the start of the TypeLevelSegment we derive from the RoleBindingDelta is one of the RoleInContexts of the domain of the inverted query, we should evaluate that query (changing part of the composition is as good as changing the whole).
So we see, that as long as the start of the TypeLevelSegment derived from the RoleBindingDelta occurs somewhere in the abstract datatype of RoleInContexts that describes the domain of the inverted query, we should pick that query and re-evaluate it.
Or, formulated differently, for each RoleInContext occurring in the domain of the QueryFunctionDescription, we can construct a key from it with the RoleInContext of the range. The query should be stored under each key.
But wait. The range of the QueryFunctionDescription can be a SUM or PRODUCT, as well. Then what?
For the various RoleInContexts in the range, we can tell a story similar to what we said above about the domain. It’s symmetrical. Given a single RoleInContext in the domain and several in the range, we should create a key with each of the latter combined with the first.
A problem arises when both domain and range have multiple RoleInContexts. Should we form the full Cartesian product of the RoleInContexts in both? It turns out we should not (see the example below): we’ll generate far more keys than will ever turn up in runtime. Now this does not lead to semantically wrong results, but it is an efficiency issue not to be snuffed at (quadratic in complexity).
There is, however, a way to generate just the required keys. For this we re-run (during this process of storing inverted queries in the DomeinFile) the process of mapping the domain to the range when we compile a fills or filledBy step.
For the filledBy step this consists of looking up, for each RoleInContext in the Domain (of the cut), its binding (an ADT RoleInContext). Then, if a target context type has been specified in the query step, we replace the context in the RoleInContexts of that binding with the specified context (It requires us to store that target context in the QueryFunctionDescription).
For the fills step, the situation is somewhat simpler. The range of a fills step is, by construction, always a simple RoleInContext ADT whose EnumeratedRoleType is completely specified by the fills’ step first parameter. If no context type is given (as a second parameter), we just use the RoleInContext as we find it as the endpoint and combine it with the RoleInContexts we find in the domain. Otherwise, we replace the context type in the end RoleInContext.
To sum up: we can construct, for each cut of an inverted query starting with the fills or filledBy step, a number of keys (TypeLevelSegments) we should store the cut under. Each TypeLevelSegment consists of two RoleInContexts; each RoleInContext consists of a ContextType and an EnumeratedRoleType.
We want to store the cuts on an EnumeratedRole. By convention we store it on the EnumeratedRole whose type is in the first (domain) RoleInContext of the compound key. We obviously don’t need that first EnumeratedRoleType in the key that we store the cuts under. So we end up with a key compounded from the ContextType of the first RoleInContext and the two parts of the second RoleInContext.
15.4.3.5. Summary: sets of inverted queries
The table below gives, for several types, the subdivided sets of inverted queries that are stored on them and how to construct the keys to index them (in runtime) and to store them (in compile/type time).
| Type | Member holding inverted queries | Key construction in runtime | Key construction in type time |
|---|---|---|---|
Property |
invertedQueries |
EnumeratedRoleType |
RoleType in Range |
Context |
invertedQueries |
EnumeratedRoleType |
RoleType in Range |
EnumeratedRole |
contextQueries |
ContextType |
ContextType in Range |
filledByInverted Queries |
ContextType Filled – ContextType Filler – EnumeratedRoleType filler |
ContextType Domain, ContextType Range, RoleType Range |
|
fillsInvertedQueries |
ContextType Filler – ContextType Filled – EnumeratedRoleType filled |
ContextType Domain, ContextType Range, RoleType Range |